
A ciência de dados tem crescido cada vez mais e uma de suas principais aplicabilidades é nos esportes, principalmente no futebol, que é o mais popular mundialmente. Em várias das técnicas de Data Science utilizadas no esporte, uma das que mais se destacam é a de agrupamento, popularmente conhecida como clustering, que pode ser utilizada para agrupar jogadores com características semelhantes e potencializar o trabalho de scouters, por exemplo. Nessa série de artigos, que inicialmente serão 5, apresentarei um projeto utilizando esta técnica com dados do FIFA 20.

Quando jogamos um game de futebol como FIFA ou PES e encaramos o modo carreira como manager, enfrentamos diversos desafios, dentre eles, contratar jogadores potenciais e que atendam a nossa demanda e estilo de jogo. Um grande problema é que, em suma, montamos times de acordo com o nosso conhecimento empírico do futebol ou com o que ouvimos falar sobre um jogador. Este tipo de atitude não é recomendado, haja vista que podemos contratar jogadores de nome, mas que não deem liga.
Geralmente, somos desafiados em times com baixo orçamento e peças limitadas e então é preciso reforçar nossa equipe. A grande pergunta nesses casos é: É possível montar um time com jogadores potenciais e com baixo valor em caixa? A resposta é sim, é possível e técnicas de Machine Learning e análise exploratória de dados podem nos ajudar nesse processo, assim como auxiliam também em situações em que temos um bom orçamento e estamos brigando “nas cabeças” em todos os campeonatos possíveis.
O objetivo do presente projeto é utilizar clustering para agrupar jogadores com características semelhantes e perguntar aos dados como esses jogadores se comportam, para encontrar nomes ideais e montar um time poderoso no FIFA. No final, montarei um time de acordo com minhas análises.
A seguir, utilizarei uma base de dados disponibilizada na plataforma Kaggle, que contém todos os jogadores possíveis do game de futebol mais famoso do mundo. Utilizarei o k-means para encontrar os grupos potenciais! O Dataset contém 104 variáveis (métricas de avaliações dos jogadores) e 18278 linhas (jogadores). Abaixo, as 5 primeiras entradas:
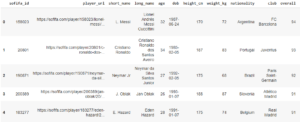
É necessário realizar uma pequena limpeza nos dados, pois há muitas variáveis que são desnecessárias para a análise em questão. Removi algumas colunas como o código identificador do jogador, sua url, valor de clausula, preço, valor de contrato, etc. Como o K-Means não aceita atributos nominais, somente numéricos, então é necessário selecionar as features necessárias.
Agruparei os jogadores conforme as seguintes métricas/características:
- Overall: é a nota geral do jogador, o que varia de 0 a 100
- Potential: Nível potencial do jogador, que também varia de 0 a 100
- Weak Foot: Habilidade com pé fraco, que varia de 1 a 5. Quando mais alto, melhor a habilidade com pé fraco.
- Skill Moves: É a habilidade de se mover, que simplesmente metrifica a qualidade o jogador para realizar certos movimentos especiais com a bola, seja para driblar ou não.
- Pace: Metrificação do ritmo do jogador, que varia de 0 a 100.
- Shooting: Métrica de qualidade dos chutes do jogador, que varia de 0 a 100.
- Passing: Métrica de qualidade dos passes do jogador, que varia de 0 a 100.
- Dribbling: Metrifica a capacidade do jogador de carregar a bola e passar por um adversário. Um valor mais alto significa que o jogador será capaz de manter melhor a posse da bola enquanto dribla, pois manterá a bola mais perto, tornando mais difícil para o adversário tomá-la.
- Defending: Métrica de qualidade para se defender de um determinado jogador, que varia de 0 a 100.
- Physic: Métrica de habilidades e competências físicas do jogador em questão, força, combatividade, fôlego e impulsão, que varia de 0 a 100.
As demais métricas utilizadas são relativas a goleiros da base de dados, como habilidade de fazer uma defesa enquanto mergulha pelo ar (diving), frequência com que o goleiro pega a bola ao invés de defendê-la e se ele a segura ou não (handling), o comprimento e a precisão dos seus arremessos longos/ chutes(kicking), a rapidez com que ele reage a um chute a gol (speed), seu posicionamento correto ao salvar seu time fazendo uma defesa, que também afeta a forma como o goleiro reage aos cruzamentos (positioning).
Feita a seleção dos atributos necessários, apliquei a técnica de normalização, deixando tudo na mesma escala para potencializar o agrupamento. Após esta etapa, é possível finalmente rodar o algoritmo e em seguida, apesar de não ser o mais eficiente, utilizar o Elbow Method para definir o número de clusters.
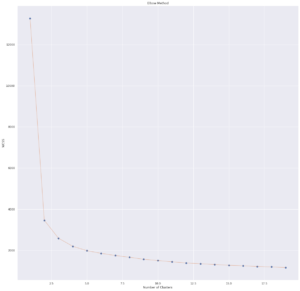
Para chegar ao número de clusters, é preciso observar em que ponto a distorção da curva começa a diminuir de forma linear. Após alguns testes, descobri que 12 clusters produzem melhores resultados. Veja como os jogadores estão distribuídos:
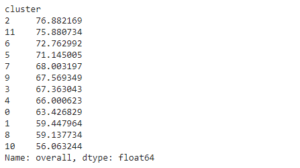
A título de curiosidade, seguem as médias do overall e potencial dos clusters.
Overall
Potencial
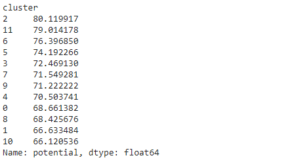
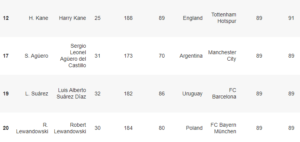
Observe a prévia de alguns jogadores do cluster 2, que é o de maior média overall e potencial e repare que faz sentido, pois os jogadores tem características semelhantes!
Agora é possível analisar cada grupo gerado e fazer as análises necessárias para montar o time, o que será apresentado nos próximos artigos.